POPIA Sections 11, 19 & 72: What They Mean for AI Architecture
A technical reading of the three POPIA sections most likely to bite an enterprise AI project, and the architectural patterns that satisfy them without a CISO memo.
The compliance officer reads POPIA as eight conditions and an enforcement chapter. The platform engineer needs three sections — 11, 19, and 72 — because those three sections govern what an enterprise AI system is technically allowed to do with personal information. This piece walks each one in plain language and maps it to the architectural pattern that satisfies it.
Section 11: Lawful processing — and why training data is processing
Section 11 of POPIA permits processing of personal information only on one of six bases: consent, contract, legal obligation, vital interest, public-body function, or legitimate interest. Most enterprise AI workflows live on consent or legitimate interest. The trap is that "processing" includes embedding, indexing, fine-tuning, and storing in a vector database — not just inference. If your AI architecture cannot justify each of those steps under one of the six bases, Section 11 is breached at the storage layer, not the model layer.
The architectural pattern is to instrument the lawful basis at the ingestion contract. Every record entering the pipeline carries a basis tag — what section permits this — and the storage layer refuses any record without one. This is cheap to build and turns a compliance question into a column lineage question. The Information Regulator's published guidance on AI specifically calls out the difference between processing the original data set and processing the model that learned from it; both are regulated, both need a basis.
The common architectural mistake is to assume that anonymisation removes the Section 11 obligation. POPIA's definition of "de-identification" is strict — it requires the information to no longer relate to an identifiable person and to be irreversible. Tokenising names and keeping behavioural patterns rarely qualifies because re-identification through inference is well-documented in the academic literature, and the Information Regulator has cited that literature in its own opinions.
Section 19: Security safeguards — what "appropriate, reasonable" means in practice
Section 19 requires the responsible party to secure the integrity and confidentiality of personal information through "appropriate, reasonable technical and organisational measures." The wording is deliberately open. For AI architecture, the working interpretation is that the safeguards must be appropriate to the sensitivity of the data and reasonable relative to the state of the art. Encryption at rest, encryption in transit, role-based access control, audit logging, and a documented incident response process form the floor — not the ceiling.
The two safeguards most often missing in enterprise AI deployments are vector-store encryption and inference-log retention. A vector store holds embeddings derived from personal information. Those embeddings can be inverted under the right conditions, which means they fall under Section 19's confidentiality requirement. Encrypting the vector store at rest with customer-managed keys is the pattern. Inference logs hold prompts and responses, both of which routinely contain personal information; logs retained without encryption and without a retention schedule are a standard finding in our governance audits.
"Organisational measures" is the part teams forget. Section 19 expects access reviews, training records, and a register of breaches. A platform that can prove access by user-by-record-by-timestamp without a query that takes two hours has built for Section 19 by architecture rather than by policy. The two are not the same.
Section 72: Cross-border transfer — the one that breaks most procurement
Section 72 prohibits the transfer of personal information outside South Africa unless one of four conditions applies: the receiving country has a law that provides adequate protection, the third party is bound by contract or binding corporate rules to comparable obligations, the data subject has consented, or the transfer is necessary to perform a contract with the data subject. South Africa has not declared any country adequate. The other three conditions scale poorly to enterprise AI workloads.
What this means for architecture is that every component touching personal information needs a residency answer. The model endpoint, the embedding endpoint, the vector store, the prompt log, the evaluation harness, and the observability tooling all count. A US-hosted model API called from a South African application processes the data the moment it crosses the wire, and that processing is a cross-border transfer for Section 72 purposes.
The Data Processing Agreement plus Standard Contractual Clauses pattern is the default contractual answer in 2026 procurement. It is workable for narrow use cases and indefensible for broad ones. The architectural alternative is to keep every component inside af-south-1 — which Bedrock, OpenSearch with vector engine, SageMaker, CloudWatch, and Athena now permit. Where a particular model is only available in another region, the pattern is a regional gateway that strips personal information before the cross-border hop and re-attaches identifiers on the response side. That is a real engineering project; it is also, in most procurement reviews, cheaper than the DPA + SCC stack over a three-year horizon.
A reference architecture that satisfies all three
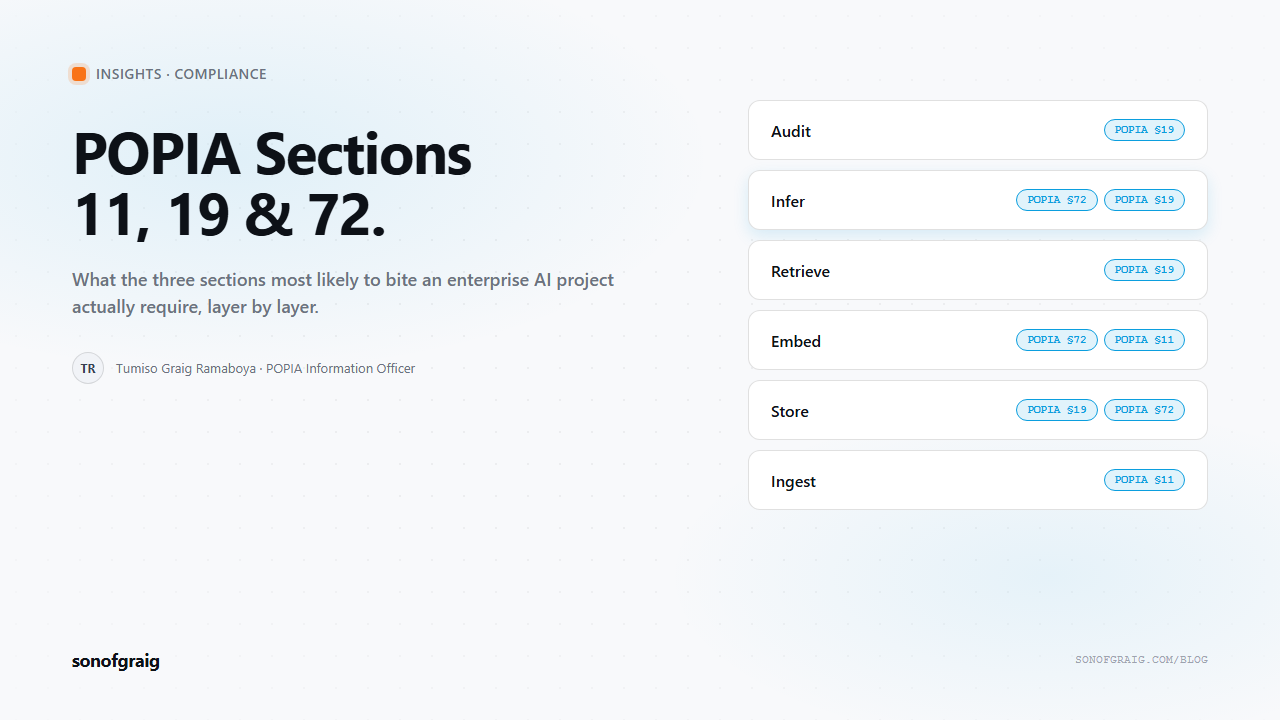
The pattern we deploy across customer engagements has six layers, each instrumented for the section that governs it:
- Ingest — every record tagged with its Section 11 lawful basis, source system, data subject category, and retention class. No row enters the pipeline without these four fields.
- Store — encryption at rest with customer-managed KMS keys (Section 19), bucket policies that deny cross-region replication by default (Section 72), and a lineage log that records every read.
- Embed — embedding model invoked in af-south-1 (Section 72), vector store encrypted with the same KMS hierarchy (Section 19), and a basis-tag column carried into the vector schema (Section 11).
- Retrieve — query-time access control filters retrieval by the calling user's authorisation scope (Section 19), and the retrieval log captures user, query, retrieved IDs, and timestamp (Section 19 organisational measure).
- Infer — model endpoint in af-south-1 (Section 72), prompts and responses logged with a configurable retention class derived from the source data's retention tag (Section 19).
- Audit — immutable append-only log accessible to the POPIA Information Officer with the access patterns Section 19 expects: by user, by record, by section, by time window. Three-year retention by default.
None of this is novel. All of it is the difference between an AI platform whose compliance story is a 40-page memo and one whose compliance story is a console you can show the Information Regulator.
Related
- Why Africa Needs Its Own Enterprise AI Platform — the strategic argument this piece supports.
- AI Governance & Ethics Audit — the services engagement that surfaces gaps against this checklist.
- Our POPIA posture page — how we satisfy these sections by architecture.
Frequently asked
- Does Section 72 ban using OpenAI from South Africa?
- It does not ban it outright. Section 72 requires one of four conditions for any cross-border transfer of personal information. The current default is a Data Processing Agreement plus Standard Contractual Clauses binding OpenAI to POPIA-comparable obligations. That is contractually workable but architecturally fragile, because the data still leaves the country and the safeguards rely on enforcement against a foreign counterparty. The architectural alternative is to invoke models that are hosted inside af-south-1, or to strip personal information at a regional gateway before any cross-border hop.
- Is anonymisation enough to take data out of POPIA scope?
- Only if it meets POPIA’s strict de-identification definition: the information must no longer relate to an identifiable person, and the de-identification must be irreversible. Tokenising names and keeping behavioural records typically does not qualify, because re-identification through inference is well-documented and the Information Regulator has cited that literature. Treating anonymisation as a Section 11 exemption without engineering proof of irreversibility is one of the more common findings in our governance audits.
- Does Section 19 require encryption at rest for vector databases?
- Section 19 does not name encryption specifically — it requires "appropriate, reasonable technical and organisational measures." For a vector store holding embeddings derived from personal information, the prevailing interpretation is that encryption at rest with customer-managed keys is the floor of what counts as appropriate. Embeddings are invertible under conditions documented in the academic literature, which brings them inside Section 19’s confidentiality scope.
- What are the penalties for a Section 11 violation in an AI context?
- The Information Regulator can issue an enforcement notice; failure to comply is an offence that can carry an administrative fine of up to R10 million or a prison sentence of up to ten years. Beyond the statutory penalty, Section 99 grants data subjects a civil claim, which in an AI context can scale to a class of every data subject whose record was processed without a valid lawful basis. The financial risk is rarely the headline issue — the reputational and procurement risk usually is.